

Will the Semantic Web allow precision searching?
Will the Semantic Web allow precision searching?
The Semantic Web requires user input to set up a links based on concept words. There are in fact META tags which a user can use which describe already what a Web Page is about. The innovation which the "Semantic Web" also known as Web 3.0 makes is to describe concepts as parts of other concepts. Eg.. a fox is a mammal, a mammal is an animal. will this type of classification alone lead to the type of precision retrieval that is claimed?
Honesty
Google, which has had extensive experience in retrieval, is :-
1) Skeptical about the Semantic web and has refused to participate.
2) Is relying less and less on user supplied metas. Google is getting wise to the fact that people are not honest when they supply metas. In fact metas have become part of "getting to the top with Google", and Google is now getting wise to this.
It is a well known fact that pornography sites use false keywords to get people in. An example is below
http://uk.pg.photos.yahoo.com/ph/pmparker6@btinternet.com/album?.dir=c6f0re2&.src=ph&store=&prodid=&.done=http%3a//uk.photos.yahoo.com/ph//my_photos
Even if people were honest surely it is the wrong way to go to get people to master new technologies.
The software that is being offered now is cumbersome. Each provider "owl" for example has a library of concept keywords. I am going to claim that what a site like owl is offering would, at best, can be done much better by a conventional database which is web enabled using an operating system.
Databases
Let us look at how a simple database works. There are a number of records which are divided into fields. Some of these fields are key fields and some are not. All the key fields have a file associated with them. This file normally accesses using a hash key of some description. File has a prime number of records and we multiply the characters in a field together within that modulus. Once we have found the first record chaining enables the other records to be rapidly found. On non key fields you simply do a comparison.
Very simple, there are complications like creating and deleting records, what the database does with its files as it starts to fill up, but these need not concern us. If you look a system such as Oracle, it is quite complicated. Oracle allows you to set up sophisticated data structures, just like, but in my opinion better, than those of the Semantic Web. Oracle, like virtually all databases allows you to put hyperlinks in your fields. It will also allow the database to be distributed.
Key Question : What is there in the Semantic Web that does not exist in Oracle?
Well the SW is a database which exists in virtual form. Oracle files, although they can be distributed tend to be based on one computer. In fact if we are using a database there are 2 questions to ask.
1) Can AI help us to maintain the database? Can we by searching through the Web get appropriate entries to put into our database.
2) Can we get an operating system which will produce a well distributed database from one.
These two questions are independent but they are related. We may find that to provide a semantic analysis of adequate power we need to operate a large number of computers in parallel. If we can get a system like tapestry http://oceanstore.cs.berkeley.edu/publications/papers/pdf/fast2003-pond.pdf
Properties we expect from operating systems
An operating system should free the user from thinking about the minutiae of how to do something. for example we do not address disc storage systems directly, we have an operating system which does this for us. Now what are the advantages of the Semantic Web over a simple database? OK a simple database is not extendable, nor is it necessarily distributed over the Web. As you can see Tapestry in Ocean Store is all these things.
http://oceanstore.cs.berkeley.edu/publications/papers/pdf/sciam-worldwide.pdf
This describes the scope of what a proper 3rd generation Internet will achieve. The authors are keen on things like SETI. Our bias has got to be the provision of adequate computer resources for semantic analysis. To achieve this we neeed a way of running programs in parallel.
http://oceanstore.cs.berkeley.edu/
24/7 operation and power
The Ocean Store team has suggested that users that are willing to share resources should get free Internet services. I think therefore it is useful to look at the energy cost of 24/7. Tapestry allows users to opt in and opt out of the system, although it is clear that for maximum gains 24/7 will be a requirement. My first reference is http://www.dansdata.com/power2.htm Note that Dan "ranted" some time ago when clock speeds were less. It should be noted that power requirements for a CPU are related to the charging and discharging of capacitors at the clock speed. About 25 watts under full load with 10-15 watts under light load is fairly typical. Disc drives take up This reference http://www.digit-life.com/articles2/storage/hddpower.html deals with disc drives which are rated at 7.5 watts. Hence total power is ~20w. A little ingenuity could reduce this further. Power will be consumed if at heavy load. However the user demanding heavy load will pay for this. There is an interesting thread in sci.physics http://groups.google.co.uk/group/sci.physics/browse_frm/thread/3f3f7c31c311bf2d/23eaf8174e80ac1f?lnk=raot&hl=en#23eaf8174e80ac1f In fact a lot of energy saving measures have been incorporated in the current generation of computers. Of course if an OS demands that your computer do some useful work this all changes - but then you are recompensed!
As we shall see later natural language processing using DCA (Discrete Combinatorial Analysis) is intensive in computer time. It is sufficiently intensive to be impracticable (though not totally) with Google as it is presently set up. However with an operating system it is a relatively small load. Let us say that we want a document to be translated from English into Spanish, Arabic or Chinese. Let us compare the time it would take to translate compared with the time it would take to compose the document. This is the relevant figure for an operating system which includes my computer as a peer. At the moment you link your computer up to a server. Only servers are peers.
Natural Language Processing and Statistical Methods
Basis of DCA/LSA
LSA views each word in a context with other words. In most implementations there either no parsing or very rudimentary parsing.. We construct vectors which consist of weighted distributions of the words surrounding the word in question. We construct a correlation matrix with the words and their surrounding vectors, this matrix is then diagonalized. What we end up with is a series of vectors. Normally the top 100 or so eigenvalues are taken. This in fact constitutes a Vector Space.
http://en.wikipedia.org/wiki/Latent_semantic_indexing
To translate we need to get the word in English and we obtain the correct word in the other language by looking at the position of the word in Vector Space.
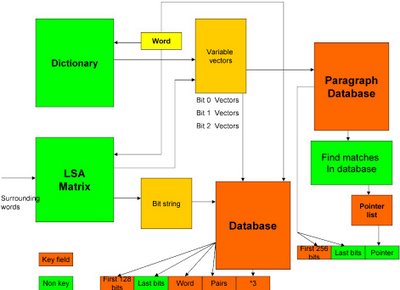
We would also like to be able to set up a retrieval database as well as a scheme for translation.
Construction of the key fields : Each word has a position in vector space. The bit configuration of a word is the combination of the surrounding wourds (LSA) and the dictionary definition. Sometimes the dictionary definition of a word contains a number of regions of vector space. A second language provides an insight into these regions. Spring is (at the moment) translated by Google as ressorte. Hence the elastic station "La estacion de ressorte". There are in fact 3 main regions - primavera, mamanthal and ressorte. LSA should get the word into the right region. The algorithm for obtaining the bit pattern (key field) is the following. The largest eigenvalue is found and the first bit is 1 if the value is above the discriminant level. The discriminant level is set initially as the mean value of all words along the eigenvector. The eigenvalue is then divided by 2 and the the discriminant level is taken to be a quartile (ie. the mean of all words who have the bit the value of 1 or 0 respectively). This process is then repeated until we have 128 bits this constitutes a key field. It is clear that as we are retrieving from a position in vector space. The remaining bits are not in the key field but are stored. In Google you can retrive quotations so we need the word, pairs of words etc. as key fields.
Lastly LSA will construct a database of paragraphs. This again has the first 128 bits as a key field with the last bits recorded. In addition to this there is a pointer to other paragraphs which are not far separated from the present paragraph in terms of Euclidean distance. It can be seen from this that the database is starting to acquire the characteristics of the Semantic Web, the difference being that this database is completely spider maintained.
There are a few other things that Google does that might be mentioned here. One of them is to maintain a list of how many people have accessed a particular website and how many hyperlinks (citations) have been put in. The more cited a website is the higher it goes in the rankings. Latent Semantic Analysis can access meaning. It cannot access quality, Google as I have said measures "quality" by the number of accesses. This is only partly satisfactory as bandwagon effects can introduce instability. There is one metric of "interest" that I appreciate as a scientist and that is a website that has an unusual list of areas of interest. Ian Stewart http://freespace.virgin.net/ianstewart.joat/index.htm has written a book on "How to cut a cake". Ian Stewart in discussing political negotiation has a number of profound insights. AI could in fact flag this on the basis of juxtapositions.
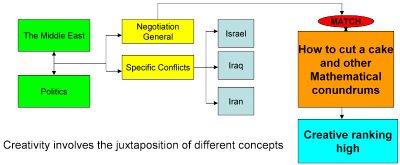
In the example above we have a database that links different concepts. The Semantic Web has these concepts produced manually. Here we have a choice. A database can be constructed by hand. Alternatively concepts can be associated by means of correlations. It should be possible to set a creativity rating in searches, that is to say the weighing which is given to novel ways of looking at things.
How much research is currently being done?
DARPA the Pentagon's advanced research has produced a program into language research called GALE http://projects.ldc.upenn.edu/gale/ . As you can see from the information provided the project appears to be in an early stage. The languages are English, Arabic and Chinese. It would appear that the project has only just started as the list of publications is blank and they are still collecting their initial data. They do by the way intend to have a list of peer reviewed papers it is not a secret project. They intend to use a variety of techniques, some of them statistical, some of them not. It would appear that LSA is going to become part of the rubric. There is general interest in the development of AI techniques for enhanced searching there are some references below.
http://www.ist-cascom.org/
http://www.timesonline.co.uk/article/0,,2095-2459650,00.html
http://www.powerset.com/
It would appear that the idea of Natural Language searching and specific enquiries is going through. The links show what is happening in the world out there. These days if an idea is sound the big boys will very quickly get on the bandwagon. Google has a secret project. One must assume that it is to do with the semantic web and linguistic analysis. Powerset has advertised the lines on which they are working, Google has not but you can bet your bottom dollar that they have a team working along similar lines.
Hakia http://home.businesswire.com/portal/site/google/index.jsp?ndmViewId=news_view&newsId=20061215005116&newsLang=en Hakia is making an attempt to produce a true ontological database. In the reference given the claims are explored. I tried out Hakia with the following results.
1) It understands the difference between primavera (Spring flowers in the Cotswolds) and mamanthal (Springs in the Cotswolds). All references were appropriate to the indicated meaning.2) One of he claims made is that it is capable of pulling in data from websites regardless of their metas. Accordingly "What is the half life of Polonium 210?" produced a website about the determination of the age of the Earth. Sure enough it contained the information, the decay path of Uranium to Lead with the half lives of all the daughter nuclei included.
Actually a true semantic search is not needed for Polonium 210, although a spider that ignores user provided metas is. We can view this question in a slightly different light. We can state a fact and ask the engine what is dependent on this fact. Viewed in this way we can see how we can develop a powerful AI engine. The answer to this question promotes another type of query. Suppose I was to ask where knowledge of the half life of polonium 210 was relevant. This type of question is extremely interesting as it would lead on to questions of a marketing nature.
Suppose I had an invention and I was trying to sell it to a (sceptical?) audience of financiers. I would want a list of all the applications that this invention might have. If I were marketing a product I would want to know who I should approach. There is a saying that it is not what you know that is important but who you know. Searches of this nature would address this. In the same way that a discoverer would like to know what the applications for a particular invention were, so the person running a particular process would like alerts on anything that would improve the position. Hence have a website and everyone will beat a path to your door.
Google :As you can see from the article in the Sunday Times (UK) Google has emphasized that in order to perform specific searches innovators will have to demonstrate that this can be done in bulk. Remember that if we have a hundred or so vectors defining the position of each word in terms of a Euclidean position this will take a lot of computer time. If we write a document by hand and want it translated into Spanish, the task is trivial - even with lots of vectors. Hence if we could have an operating system which could tap into the unused time of the various PCs the problem could be solved, and that operating systems were important.
Speech: As I have already stated speech can be decoded using semantic analysis. The phoneme recognition package assigns a probability to each possibility. Vectors are then evaluated using these probabilities. The resultant positions in Vector Space then generate new probabilities, these are then refined until every word is defined with a given (say 99%) certainty. As individual phonemes can be recognized as well as, or better than, a human listener speech will be recovered from any reasonable meaning assignment system.
Operating Systems: Operating systems are important from two other point of view. They are needed to limit access to data to authorized recipients. remember that the system being envisaged will be immensely powerful. If we ask the question "how many firms did IBM take over in the last 5 years?" you can just as easily ask the question "Give me a complete profile of Ian Parker". This means that all the data accumulated by spiders has to be held under secure conditions. This,, in effect, means that an operating system needs to be in control of the data which the spiders are generating. The other function of the operating system is that it provides for a series of alerts useful in object oriented programming.
What perhaps we should be asking in this group is what sort of API we would want from Google, or anyone else for that matter. If our ultimate goal is reasoning ability we would like to look at how an API might help us. People have from time to time suggested that we should attempt to get computers to write in C++ or Java. A little thought however tells us that not only is this an unrealistic aim but also an unnecessary one. There is lots and lots of software out there. If we have a precision retrieval system we can get code to do whatever we want. Hence out API has to be a source of both classes, methods and data. If we are programming in what might be described as an "object orientated" way we fire up our method. We have a difficulty here. Pieces of software are often incompatible because the arguments for subroutines are presented in slightly different ways. Let us take a simple example. A rectangle needs 4 quantities to specify it, its position and its two sides. This can be given in a number of different ways. It can be given for example as 2 opposite points. Hence we need a rectangle class which will accept data in all forms. The class will evaluate whether of not the class has been completely specified or not.
Mathematics can in many ways be considered to be the manipulation of abstract symbols. Pseudocode has been used for a number of years to demonstrate the correctness of a piece of code. There is one fact about modern mathematics which will surprise people and that is how little computers are used in terms of proofs. Not strictly true - the four colour theorem was proved by a computer. A number of people have written about this in sci.maths - many to the effect that modern mathematics is a fraud! No it isn't, but the point is that the provision of initial symbolic concepts is best done by hand - this is the essence of what constitutes mathematics. When problems get complex to solve then we use a computer. This tells us that the initial evaluation of classes will have to be done by hand. Once we get a fair number of classes which can be evaluated on a general set of data these will exist on the Web.
One question - How do we think about things? well we think by association and we think symbolically. That is to say we are not in the habit of using complicated methods. If I were asked the question which I have alluded to - "Do the angles of a triangle add up to 180 degrees?". This occurred in a conversation with the recent Turing winner. What do I associate angles of a triangle with? I associate it with the axioms of Euclid. I also associate Euclid with non Euclidean geometry. Where in Physics do we meet curvature of space? General relativity - theory of gravitation. Hence my statement that if my bunch of keys falls the angles of a triangle cannot add up to 180. Note we are not working out any method. I happen to know that quasars are powered by black holes which can convert up to 80% of rest mass into energy, but I am NOT calculating a method. Thus in many ways our thoughts may be described in an Erdos way with us connecting concepts rather than individuals.
This now is perhaps telling us something about the interface, or API should look like. A search engine needs to fill up a local database. The reason why we need a local database is because a module will be receiving data, performing calculations and outputting. This output may be used as the basis of other programs. The formatted output is placed in a local database. As soon as data arrives either from a web spider or from a program running on the system an operating system alert is raised. Would programs do real work, such as calculating the track of matter in a spinning black hole (galactic jet) or would they simply do symbolic manipulations. It would all depend on the precise application. Symbolic manipulations which produced associations could also call upon information relevant to that association.
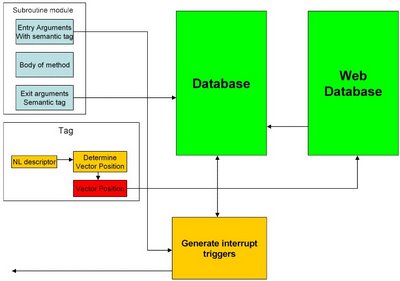
Suppose we pose a question. which involves us in going from P to Q. We have a number of operands which will produce symbolic results Presented in this way the problem appears to be similar to the Erdos problem. We label symbolic output with a label of some description and that serves both to create a symbolic path and to be a basis for an internal database. Exactly the same procedure enables us to design something P -> P will represent a Von Neumann machine.
What are the viable alternative approaches? I tend to think not for the following reasons. Any approach to AI - any at all must involve implicit bueno espagnol since if we have reasoning ability we have the implicit translation of NL into ideas. To be sure there are other fields of AI which are not linguistically based like pattern recognition, robotics and positional awareness. In fact the problem can be stated in even more general terms. We may say that iff (2 fs deliberate as we shall see) we have a description of something we can start reasoning, even if that reasoning process is very much a trial and error genetic algorithm. In terms of genetic algorithms we may say that a definition of fitness is what is required for reasoning. This is so since if we know what fitness is we can get together a collection of parameters (remember if we have a description of something we can always derive a set of parameters).
We have seen that a description will generate (at least) a genetic algorithm which will take us from State A to state B. If we have a state that is undefined there cannot be an algorithm which connects one state to another. Suppose we say in a Horn clause "The spring is warm" Does this mean primavera possibly, but it could refer to a warm string like the one at Bath it could even refer to Harrison contemplating his voyage to the West Indies and how to compensate for temperature. So all three primavera, mamanthal and ressorte are possible. Would a Cyc type system enable us to translate? Yes, eventually, but there seem to be far better methods available.
Summary
The short answer to the question is "no". If we look for a Web 3.0 we look for a better basic operating system, not just a new application. The key to AI and the main unsolved question is natural language translation. The Semantic Web is definitely 2.*. In fact with a true 3.0 the whole of the Semantic Web begins to look trivial, since any database can be spread over the WEb. http://ipai.blogspot.com/ is a previous blog which shows this.
The Semantic Web requires user input to set up a links based on concept words. There are in fact META tags which a user can use which describe already what a Web Page is about. The innovation which the "Semantic Web" also known as Web 3.0 makes is to describe concepts as parts of other concepts. Eg.. a fox is a mammal, a mammal is an animal. will this type of classification alone lead to the type of precision retrieval that is claimed?
Honesty
Google, which has had extensive experience in retrieval, is :-
1) Skeptical about the Semantic web and has refused to participate.
2) Is relying less and less on user supplied metas. Google is getting wise to the fact that people are not honest when they supply metas. In fact metas have become part of "getting to the top with Google", and Google is now getting wise to this.
It is a well known fact that pornography sites use false keywords to get people in. An example is below
http://uk.pg.photos.yahoo.com/ph/pmparker6@btinternet.com/album?.dir=c6f0re2&.src=ph&store=&prodid=&.done=http%3a//uk.photos.yahoo.com/ph//my_photos
Even if people were honest surely it is the wrong way to go to get people to master new technologies.
The software that is being offered now is cumbersome. Each provider "owl" for example has a library of concept keywords. I am going to claim that what a site like owl is offering would, at best, can be done much better by a conventional database which is web enabled using an operating system.
Databases
Let us look at how a simple database works. There are a number of records which are divided into fields. Some of these fields are key fields and some are not. All the key fields have a file associated with them. This file normally accesses using a hash key of some description. File has a prime number of records and we multiply the characters in a field together within that modulus. Once we have found the first record chaining enables the other records to be rapidly found. On non key fields you simply do a comparison.
Very simple, there are complications like creating and deleting records, what the database does with its files as it starts to fill up, but these need not concern us. If you look a system such as Oracle, it is quite complicated. Oracle allows you to set up sophisticated data structures, just like, but in my opinion better, than those of the Semantic Web. Oracle, like virtually all databases allows you to put hyperlinks in your fields. It will also allow the database to be distributed.
Key Question : What is there in the Semantic Web that does not exist in Oracle?
Well the SW is a database which exists in virtual form. Oracle files, although they can be distributed tend to be based on one computer. In fact if we are using a database there are 2 questions to ask.
1) Can AI help us to maintain the database? Can we by searching through the Web get appropriate entries to put into our database.
2) Can we get an operating system which will produce a well distributed database from one.
These two questions are independent but they are related. We may find that to provide a semantic analysis of adequate power we need to operate a large number of computers in parallel. If we can get a system like tapestry http://oceanstore.cs.berkeley.edu/publications/papers/pdf/fast2003-pond.pdf
Properties we expect from operating systems
An operating system should free the user from thinking about the minutiae of how to do something. for example we do not address disc storage systems directly, we have an operating system which does this for us. Now what are the advantages of the Semantic Web over a simple database? OK a simple database is not extendable, nor is it necessarily distributed over the Web. As you can see Tapestry in Ocean Store is all these things.
http://oceanstore.cs.berkeley.edu/publications/papers/pdf/sciam-worldwide.pdf
This describes the scope of what a proper 3rd generation Internet will achieve. The authors are keen on things like SETI. Our bias has got to be the provision of adequate computer resources for semantic analysis. To achieve this we neeed a way of running programs in parallel.
http://oceanstore.cs.berkeley.edu/
24/7 operation and power
The Ocean Store team has suggested that users that are willing to share resources should get free Internet services. I think therefore it is useful to look at the energy cost of 24/7. Tapestry allows users to opt in and opt out of the system, although it is clear that for maximum gains 24/7 will be a requirement. My first reference is http://www.dansdata.com/power2.htm Note that Dan "ranted" some time ago when clock speeds were less. It should be noted that power requirements for a CPU are related to the charging and discharging of capacitors at the clock speed. About 25 watts under full load with 10-15 watts under light load is fairly typical. Disc drives take up This reference http://www.digit-life.com/articles2/storage/hddpower.html deals with disc drives which are rated at 7.5 watts. Hence total power is ~20w. A little ingenuity could reduce this further. Power will be consumed if at heavy load. However the user demanding heavy load will pay for this. There is an interesting thread in sci.physics http://groups.google.co.uk/group/sci.physics/browse_frm/thread/3f3f7c31c311bf2d/23eaf8174e80ac1f?lnk=raot&hl=en#23eaf8174e80ac1f In fact a lot of energy saving measures have been incorporated in the current generation of computers. Of course if an OS demands that your computer do some useful work this all changes - but then you are recompensed!
As we shall see later natural language processing using DCA (Discrete Combinatorial Analysis) is intensive in computer time. It is sufficiently intensive to be impracticable (though not totally) with Google as it is presently set up. However with an operating system it is a relatively small load. Let us say that we want a document to be translated from English into Spanish, Arabic or Chinese. Let us compare the time it would take to translate compared with the time it would take to compose the document. This is the relevant figure for an operating system which includes my computer as a peer. At the moment you link your computer up to a server. Only servers are peers.
Natural Language Processing and Statistical Methods
Basis of DCA/LSA
LSA views each word in a context with other words. In most implementations there either no parsing or very rudimentary parsing.. We construct vectors which consist of weighted distributions of the words surrounding the word in question. We construct a correlation matrix with the words and their surrounding vectors, this matrix is then diagonalized. What we end up with is a series of vectors. Normally the top 100 or so eigenvalues are taken. This in fact constitutes a Vector Space.
http://en.wikipedia.org/wiki/Latent_semantic_indexing
To translate we need to get the word in English and we obtain the correct word in the other language by looking at the position of the word in Vector Space.
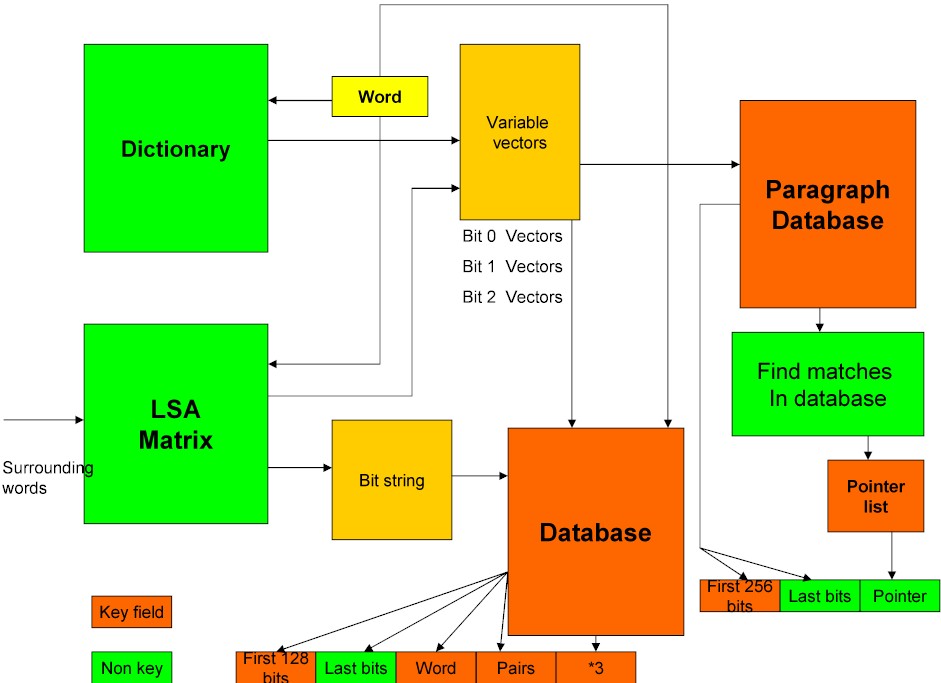
We would also like to be able to set up a retrieval database as well as a scheme for translation.
Construction of the key fields : Each word has a position in vector space. The bit configuration of a word is the combination of the surrounding wourds (LSA) and the dictionary definition. Sometimes the dictionary definition of a word contains a number of regions of vector space. A second language provides an insight into these regions. Spring is (at the moment) translated by Google as ressorte. Hence the elastic station "La estacion de ressorte". There are in fact 3 main regions - primavera, mamanthal and ressorte. LSA should get the word into the right region. The algorithm for obtaining the bit pattern (key field) is the following. The largest eigenvalue is found and the first bit is 1 if the value is above the discriminant level. The discriminant level is set initially as the mean value of all words along the eigenvector. The eigenvalue is then divided by 2 and the the discriminant level is taken to be a quartile (ie. the mean of all words who have the bit the value of 1 or 0 respectively). This process is then repeated until we have 128 bits this constitutes a key field. It is clear that as we are retrieving from a position in vector space. The remaining bits are not in the key field but are stored. In Google you can retrive quotations so we need the word, pairs of words etc. as key fields.
Lastly LSA will construct a database of paragraphs. This again has the first 128 bits as a key field with the last bits recorded. In addition to this there is a pointer to other paragraphs which are not far separated from the present paragraph in terms of Euclidean distance. It can be seen from this that the database is starting to acquire the characteristics of the Semantic Web, the difference being that this database is completely spider maintained.
There are a few other things that Google does that might be mentioned here. One of them is to maintain a list of how many people have accessed a particular website and how many hyperlinks (citations) have been put in. The more cited a website is the higher it goes in the rankings. Latent Semantic Analysis can access meaning. It cannot access quality, Google as I have said measures "quality" by the number of accesses. This is only partly satisfactory as bandwagon effects can introduce instability. There is one metric of "interest" that I appreciate as a scientist and that is a website that has an unusual list of areas of interest. Ian Stewart http://freespace.virgin.net/ianstewart.joat/index.htm has written a book on "How to cut a cake". Ian Stewart in discussing political negotiation has a number of profound insights. AI could in fact flag this on the basis of juxtapositions.
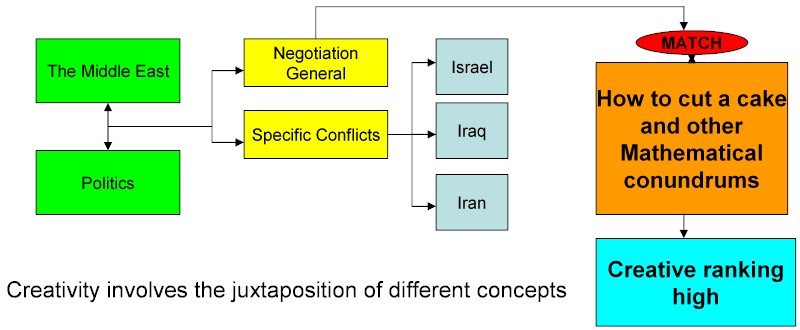
In the example above we have a database that links different concepts. The Semantic Web has these concepts produced manually. Here we have a choice. A database can be constructed by hand. Alternatively concepts can be associated by means of correlations. It should be possible to set a creativity rating in searches, that is to say the weighing which is given to novel ways of looking at things.
How much research is currently being done?
DARPA the Pentagon's advanced research has produced a program into language research called GALE http://projects.ldc.upenn.edu/gale/ . As you can see from the information provided the project appears to be in an early stage. The languages are English, Arabic and Chinese. It would appear that the project has only just started as the list of publications is blank and they are still collecting their initial data. They do by the way intend to have a list of peer reviewed papers it is not a secret project. They intend to use a variety of techniques, some of them statistical, some of them not. It would appear that LSA is going to become part of the rubric. There is general interest in the development of AI techniques for enhanced searching there are some references below.
http://www.ist-cascom.org/
http://www.timesonline.co.uk/article/0,,2095-2459650,00.html
http://www.powerset.com/
It would appear that the idea of Natural Language searching and specific enquiries is going through. The links show what is happening in the world out there. These days if an idea is sound the big boys will very quickly get on the bandwagon. Google has a secret project. One must assume that it is to do with the semantic web and linguistic analysis. Powerset has advertised the lines on which they are working, Google has not but you can bet your bottom dollar that they have a team working along similar lines.
Hakia http://home.businesswire.com/portal/site/google/index.jsp?ndmViewId=news_view&newsId=20061215005116&newsLang=en Hakia is making an attempt to produce a true ontological database. In the reference given the claims are explored. I tried out Hakia with the following results.
1) It understands the difference between primavera (Spring flowers in the Cotswolds) and mamanthal (Springs in the Cotswolds). All references were appropriate to the indicated meaning.2) One of he claims made is that it is capable of pulling in data from websites regardless of their metas. Accordingly "What is the half life of Polonium 210?" produced a website about the determination of the age of the Earth. Sure enough it contained the information, the decay path of Uranium to Lead with the half lives of all the daughter nuclei included.
Actually a true semantic search is not needed for Polonium 210, although a spider that ignores user provided metas is. We can view this question in a slightly different light. We can state a fact and ask the engine what is dependent on this fact. Viewed in this way we can see how we can develop a powerful AI engine. The answer to this question promotes another type of query. Suppose I was to ask where knowledge of the half life of polonium 210 was relevant. This type of question is extremely interesting as it would lead on to questions of a marketing nature.
Suppose I had an invention and I was trying to sell it to a (sceptical?) audience of financiers. I would want a list of all the applications that this invention might have. If I were marketing a product I would want to know who I should approach. There is a saying that it is not what you know that is important but who you know. Searches of this nature would address this. In the same way that a discoverer would like to know what the applications for a particular invention were, so the person running a particular process would like alerts on anything that would improve the position. Hence have a website and everyone will beat a path to your door.
Google :As you can see from the article in the Sunday Times (UK) Google has emphasized that in order to perform specific searches innovators will have to demonstrate that this can be done in bulk. Remember that if we have a hundred or so vectors defining the position of each word in terms of a Euclidean position this will take a lot of computer time. If we write a document by hand and want it translated into Spanish, the task is trivial - even with lots of vectors. Hence if we could have an operating system which could tap into the unused time of the various PCs the problem could be solved, and that operating systems were important.
Speech: As I have already stated speech can be decoded using semantic analysis. The phoneme recognition package assigns a probability to each possibility. Vectors are then evaluated using these probabilities. The resultant positions in Vector Space then generate new probabilities, these are then refined until every word is defined with a given (say 99%) certainty. As individual phonemes can be recognized as well as, or better than, a human listener speech will be recovered from any reasonable meaning assignment system.
Operating Systems: Operating systems are important from two other point of view. They are needed to limit access to data to authorized recipients. remember that the system being envisaged will be immensely powerful. If we ask the question "how many firms did IBM take over in the last 5 years?" you can just as easily ask the question "Give me a complete profile of Ian Parker". This means that all the data accumulated by spiders has to be held under secure conditions. This,, in effect, means that an operating system needs to be in control of the data which the spiders are generating. The other function of the operating system is that it provides for a series of alerts useful in object oriented programming.
What perhaps we should be asking in this group is what sort of API we would want from Google, or anyone else for that matter. If our ultimate goal is reasoning ability we would like to look at how an API might help us. People have from time to time suggested that we should attempt to get computers to write in C++ or Java. A little thought however tells us that not only is this an unrealistic aim but also an unnecessary one. There is lots and lots of software out there. If we have a precision retrieval system we can get code to do whatever we want. Hence out API has to be a source of both classes, methods and data. If we are programming in what might be described as an "object orientated" way we fire up our method. We have a difficulty here. Pieces of software are often incompatible because the arguments for subroutines are presented in slightly different ways. Let us take a simple example. A rectangle needs 4 quantities to specify it, its position and its two sides. This can be given in a number of different ways. It can be given for example as 2 opposite points. Hence we need a rectangle class which will accept data in all forms. The class will evaluate whether of not the class has been completely specified or not.
Mathematics can in many ways be considered to be the manipulation of abstract symbols. Pseudocode has been used for a number of years to demonstrate the correctness of a piece of code. There is one fact about modern mathematics which will surprise people and that is how little computers are used in terms of proofs. Not strictly true - the four colour theorem was proved by a computer. A number of people have written about this in sci.maths - many to the effect that modern mathematics is a fraud! No it isn't, but the point is that the provision of initial symbolic concepts is best done by hand - this is the essence of what constitutes mathematics. When problems get complex to solve then we use a computer. This tells us that the initial evaluation of classes will have to be done by hand. Once we get a fair number of classes which can be evaluated on a general set of data these will exist on the Web.
One question - How do we think about things? well we think by association and we think symbolically. That is to say we are not in the habit of using complicated methods. If I were asked the question which I have alluded to - "Do the angles of a triangle add up to 180 degrees?". This occurred in a conversation with the recent Turing winner. What do I associate angles of a triangle with? I associate it with the axioms of Euclid. I also associate Euclid with non Euclidean geometry. Where in Physics do we meet curvature of space? General relativity - theory of gravitation. Hence my statement that if my bunch of keys falls the angles of a triangle cannot add up to 180. Note we are not working out any method. I happen to know that quasars are powered by black holes which can convert up to 80% of rest mass into energy, but I am NOT calculating a method. Thus in many ways our thoughts may be described in an Erdos way with us connecting concepts rather than individuals.
This now is perhaps telling us something about the interface, or API should look like. A search engine needs to fill up a local database. The reason why we need a local database is because a module will be receiving data, performing calculations and outputting. This output may be used as the basis of other programs. The formatted output is placed in a local database. As soon as data arrives either from a web spider or from a program running on the system an operating system alert is raised. Would programs do real work, such as calculating the track of matter in a spinning black hole (galactic jet) or would they simply do symbolic manipulations. It would all depend on the precise application. Symbolic manipulations which produced associations could also call upon information relevant to that association.
Suppose we pose a question. which involves us in going from P to Q. We have a number of operands which will produce symbolic results Presented in this way the problem appears to be similar to the Erdos problem. We label symbolic output with a label of some description and that serves both to create a symbolic path and to be a basis for an internal database. Exactly the same procedure enables us to design something P -> P will represent a Von Neumann machine.
What are the viable alternative approaches? I tend to think not for the following reasons. Any approach to AI - any at all must involve implicit bueno espagnol since if we have reasoning ability we have the implicit translation of NL into ideas. To be sure there are other fields of AI which are not linguistically based like pattern recognition, robotics and positional awareness. In fact the problem can be stated in even more general terms. We may say that iff (2 fs deliberate as we shall see) we have a description of something we can start reasoning, even if that reasoning process is very much a trial and error genetic algorithm. In terms of genetic algorithms we may say that a definition of fitness is what is required for reasoning. This is so since if we know what fitness is we can get together a collection of parameters (remember if we have a description of something we can always derive a set of parameters).
We have seen that a description will generate (at least) a genetic algorithm which will take us from State A to state B. If we have a state that is undefined there cannot be an algorithm which connects one state to another. Suppose we say in a Horn clause "The spring is warm" Does this mean primavera possibly, but it could refer to a warm string like the one at Bath it could even refer to Harrison contemplating his voyage to the West Indies and how to compensate for temperature. So all three primavera, mamanthal and ressorte are possible. Would a Cyc type system enable us to translate? Yes, eventually, but there seem to be far better methods available.
Summary
The short answer to the question is "no". If we look for a Web 3.0 we look for a better basic operating system, not just a new application. The key to AI and the main unsolved question is natural language translation. The Semantic Web is definitely 2.*. In fact with a true 3.0 the whole of the Semantic Web begins to look trivial, since any database can be spread over the WEb. http://ipai.blogspot.com/ is a previous blog which shows this.
posted by Ian Parker | 6:37 AM
|
0 comments
![]()